
熱門標簽:
pdf轉換word文檔全是圖片?

轉轉大師PDF轉換器
支持40多種格式轉換,高效辦公
 馬上下載
馬上下載
原因:
會出現這個問題是由于您的PDF文件是掃描版或者是由圖片生成的PDF,里面并沒有真正的文字。
解決方法:
這個問題就需要使用ocr文字識別功能了,可以下載轉轉大師ocr文字識別(官網地址:http://pdf.55.la/)工具,可以識別掃描版PDF中的文字。
工具下載,安裝好之后,就可以進行轉換了。
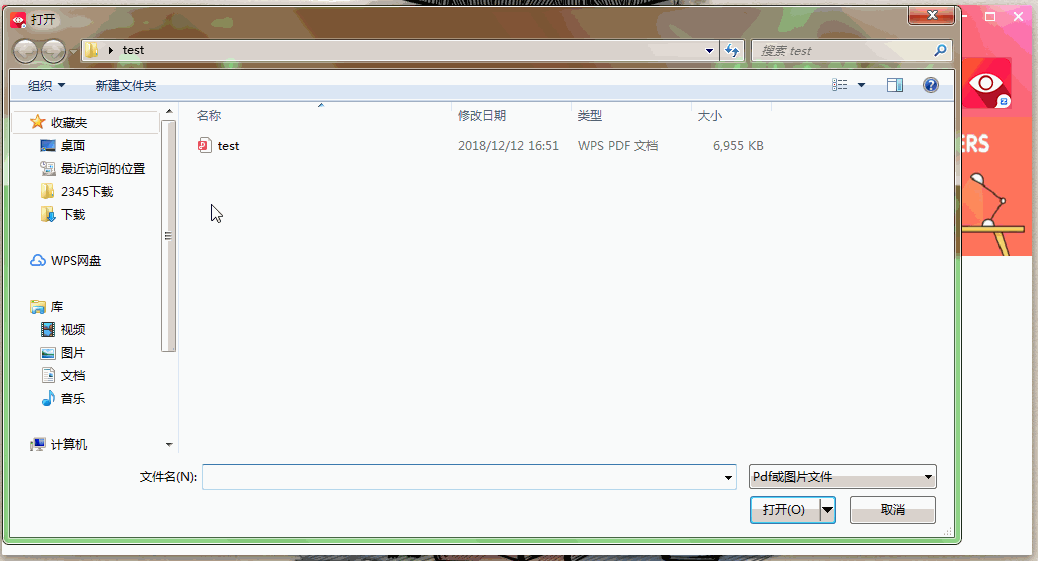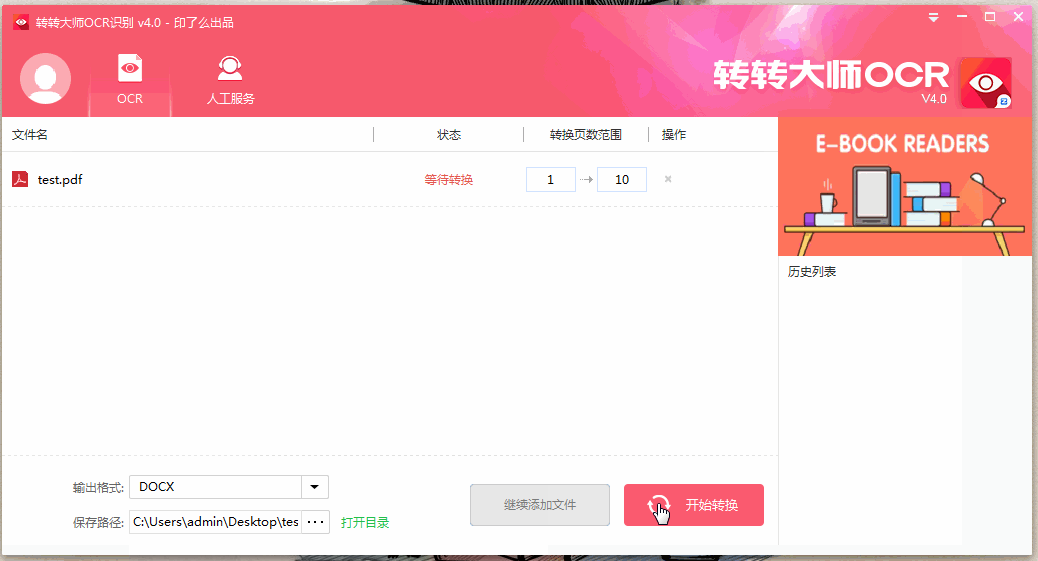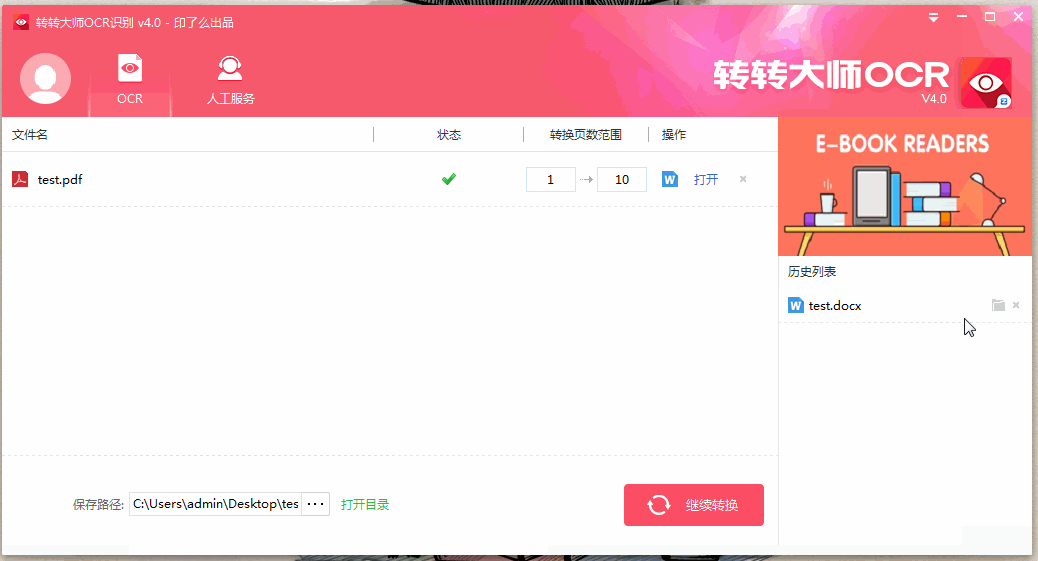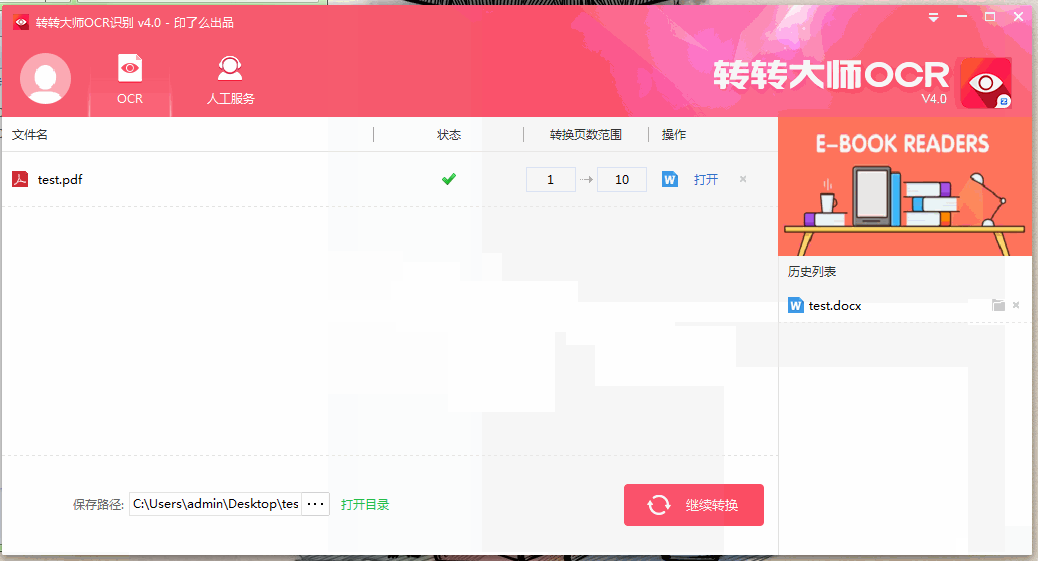
第一步:點擊圖中的“+”,選擇要轉換的文件。
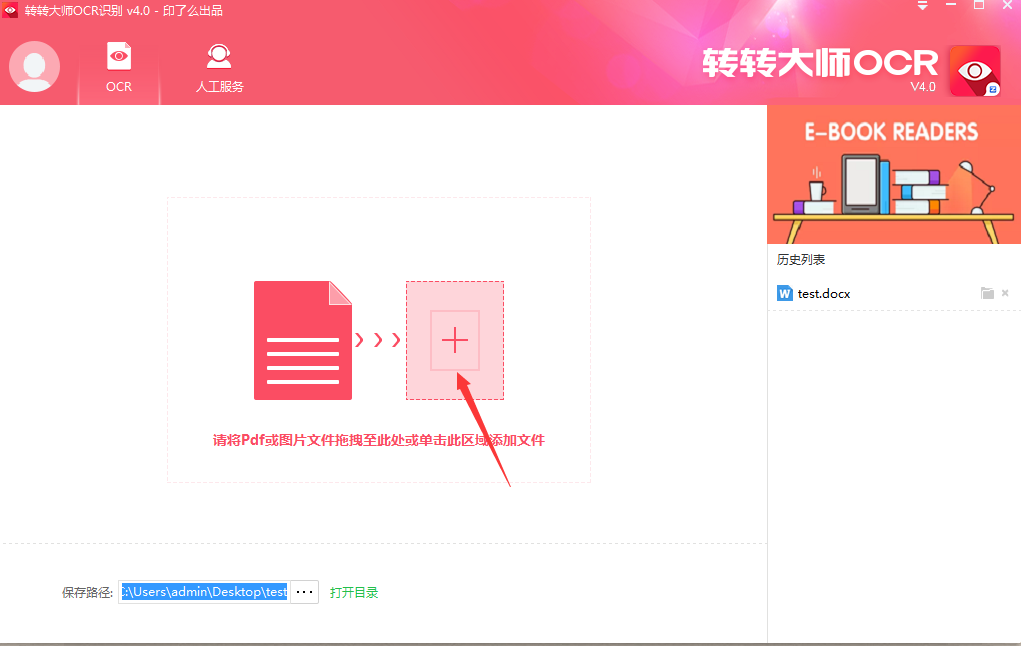
第二步:文件上傳之后,確定好輸出格式和保存路徑,然后點擊“開始轉換”。
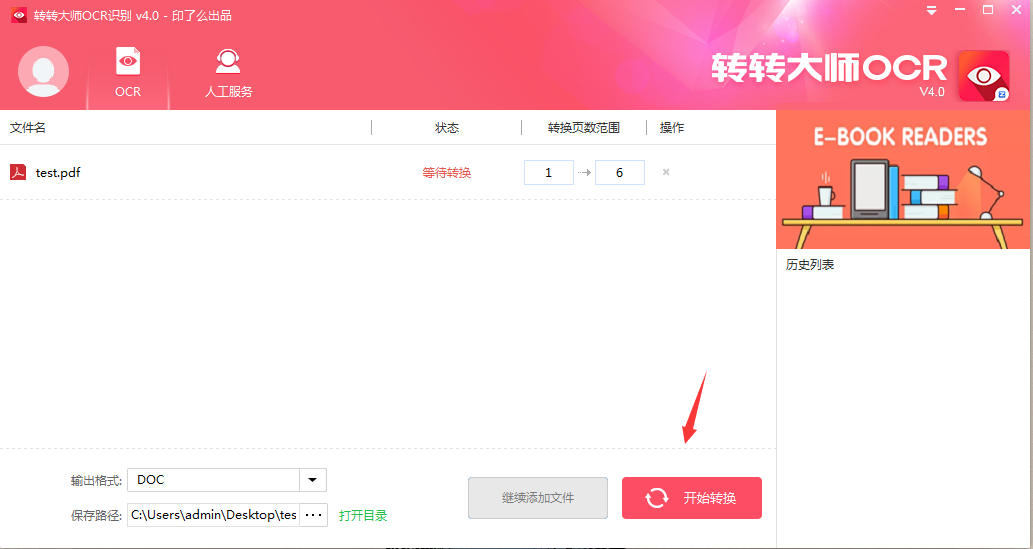
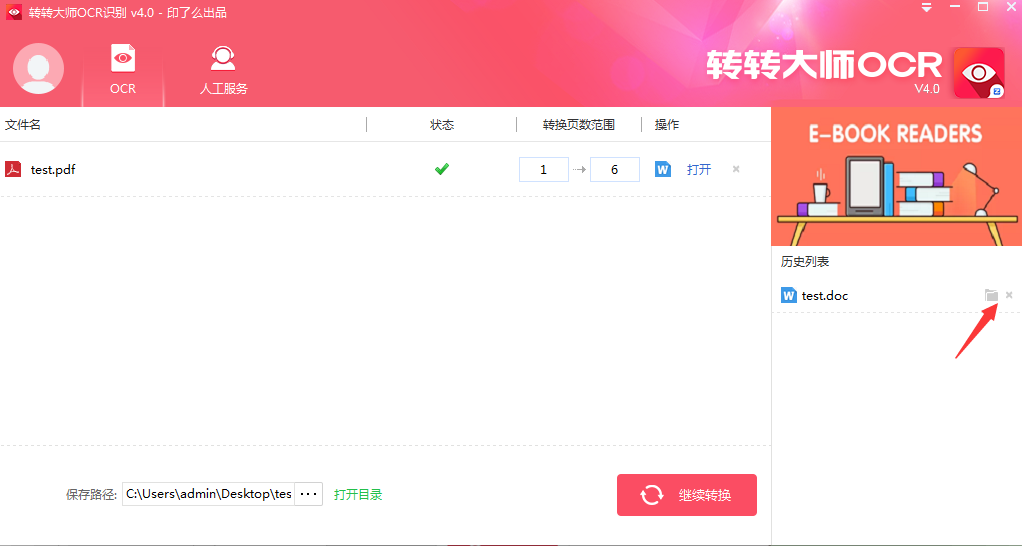
第三步,稍等片刻,轉換完成之后,點擊歷史列表中的“文件夾”圖標,即可找到轉換好的文檔。
具體操作的動態過程如下所示:
按照上述操作,即可完成文字識別。如果還有其他疑問,可以聯系客服解決。
會出現這個問題是由于您的PDF文件是掃描版或者是由圖片生成的PDF,里面并沒有真正的文字。
解決方法:
這個問題就需要使用ocr文字識別功能了,可以下載轉轉大師ocr文字識別(官網地址:http://pdf.55.la/)工具,可以識別掃描版PDF中的文字。
工具下載,安裝好之后,就可以進行轉換了。
第一步:點擊圖中的“+”,選擇要轉換的文件。
第二步:文件上傳之后,確定好輸出格式和保存路徑,然后點擊“開始轉換”。
第三步,稍等片刻,轉換完成之后,點擊歷史列表中的“文件夾”圖標,即可找到轉換好的文檔。
具體操作的動態過程如下所示:
按照上述操作,即可完成文字識別。如果還有其他疑問,可以聯系客服解決。
上一篇:word如何輕松移動段落
下一篇:文件超出50M限制,怎么辦?

 閩公網安備 閩ICP備16005963號-3
閩公網安備 閩ICP備16005963號-3